Provides both a forked process and threaded parallelization options. To
use add `parallelize` to your test suite.
Takes a `workers` argument that controls how many times the process
is forked. For each process a new database will be created suffixed
with the worker number; test-database-0 and test-database-1
respectively.
If `ENV["PARALLEL_WORKERS"]` is set the workers argument will be ignored
and the environment variable will be used instead. This is useful for CI
environments, or other environments where you may need more workers than
you do for local testing.
If the number of workers is set to `1` or fewer, the tests will not be
parallelized.
The default parallelization method is to fork processes. If you'd like to
use threads instead you can pass `with: :threads` to the `parallelize`
method. Note the threaded parallelization does not create multiple
database and will not work with system tests at this time.
parallelize(workers: 2, with: :threads)
The threaded parallelization uses Minitest's parallel exector directly.
The processes paralleliztion uses a Ruby Drb server.
For parallelization via threads a setup hook and cleanup hook are
provided.
```
class ActiveSupport::TestCase
parallelize_setup do |worker|
# setup databases
end
parallelize_teardown do |worker|
# cleanup database
end
parallelize(workers: 2)
end
```
[Eileen M. Uchitelle, Aaron Patterson]
See https://github.com/rails/rails/pull/31957#issuecomment-364817423
The purpose of `--force` is not to have any prompt whether a file should
be kept or overwritten. In general, all existing files should be overwritten.
However, `config/master.key` is special because it is git-ignored, and
overwriting it will cause the app not to run (since there won't be a way
to decrypt the credentials).
As a result, it's probably better to keep the existing config/master.key.
Incompatible settings are included in the settings set by `load_defaults`.
So, I think that target version should be updated by a user when becomes
available, and should not be updated with `app:update`.
This is similar to #30700 which ensures the `--quiet` option of `rails new`
is respected by the `MasterKeyGenerator` (missing from #30067).
Before this commit, running `rails new app --force` would still prompt the
user what to do with the conflict in `config/master.key`:
```
…
identical config/locales/en.yml
conflict config/master.key
Overwrite /Users/claudiob/Desktop/pizza/config/master.key? (enter "h" for help) [Ynaqdh]
```
After this commit, `config/master.key` is overwritten:
```
…
identical config/locales/en.yml
force config/master.key
append .gitignore
```
The newly added test generates an app and then generates it again with
`--force`. Without this commit, the test would just wait forever for user
input.
Appropriate way to handle encrypted command is by `bin/rails credentials` and
`bin/rails encrypted`
It was displayed on `bin/rails generate` command:
```
Please choose a generator below.
Rails:
application_record
assets
channel
controller
encrypted_file
encryption_key_file
generator
...
```
Before this patch, to be able to use webpacker and webconsole we were
defining an used default in the script-src policy. White we don't
implement the automatic nonce approach defined in
https://github.com/rails/rails/issues/31689 it is better to not have any
default configuration in Rails 5.2.
Previously, the `bin/yarn` wrapper would "unquote" arguments to yarn like this:
`yarn run add-copyright "(c) 2017, 2018 MyCompany"`
That results in an ARGV of ['run', 'add-copyright', '(c) 2017, 2018 MyCompany'] in the yarn wrapper,
but a ARGV in the yarn executable of ['run', 'add-copyright', '(c)', '2017,', '2018', MyCompany']
down is only called with a block from the rake tasks where it passes a
`SCOPE`. Technically this was tested but since we don't run all the
migrations we're not actually testing the down works with a `SCOPE`. To
ensure we're testing both we can run `db:migrate` again to migrate users
and then run `down` with a scope to test that only the bukkits migration
is reverted.
Updates test to prevent having to fix regressions like we did in
4d4db4c.
This reverts commit edc54fd2068bc21f0d381228e55d97e32f508923, reversing
changes made to a5922f132f4d163e2c7f770427087f5268c18def.
As discussed, this is not an appropriate place to make assumptions about
ARGV, or to write to stdout: config/boot.rb is a library and is required
by other applictions, with which we have no right to interfere.
Rails has some support for multiple databases but it can be hard to
handle migrations with those. The easiest way to implement multiple
databases is to contain migrations into their own folder ("db/migrate"
for the primary db and "db/seconddb_migrate" for the second db). Without
this you would need to write code that allowed you to switch connections
in migrations. I can tell you from experience that is not a fun way to
implement multiple databases.
This refactoring is a pre-requisite for implementing other features
related to parallel testing and improved handling for multiple
databases.
The refactoring here moves the class methods from the `Migrator` class
into it's own new class `MigrationContext`. The goal was to move the
`migrations_paths` method off of the `Migrator` class and onto the
connection. This allows users to do the following in their
`database.yml`:
```
development:
adapter: mysql2
username: root
password:
development_seconddb:
adapter: mysql2
username: root
password:
migrations_paths: "db/second_db_migrate"
```
Migrations for the `seconddb` can now be store in the
`db/second_db_migrate` directory. Migrations for the primary database
are stored in `db/migrate`".
The refactoring here drastically reduces the internal API for migrations
since we don't need to pass `migrations_paths` around to every single
method. Additionally this change does not require any Rails applications
to make changes unless they want to use the new public API. All of the
class methods from the `Migrator` class were `nodoc`'d except for the
`migrations_paths` and `migrations_path` getter/setters respectively.
### Summary
This PR changes .rubocop.yml.
Regarding the code using `if ... else ... end`, I think the coding style
that Rails expects is as follows.
```ruby
var = if cond
a
else
b
end
```
However, the current .rubocop.yml setting does not offense for the
following code.
```ruby
var = if cond
a
else
b
end
```
I think that the above code expects offense to be warned.
Moreover, the layout by autocorrect is unnatural.
```ruby
var = if cond
a
else
b
end
```
This PR adds a setting to .rubocop.yml to make an offense warning and
autocorrect as expected by the coding style.
And this change also fixes `case ... when ... end` together.
Also this PR itself is an example that arranges the layout using
`rubocop -a`.
### Other Information
Autocorrect of `Lint/EndAlignment` cop is `false` by default.
https://github.com/bbatsov/rubocop/blob/v0.51.0/config/default.yml#L1443
This PR changes this value to `true`.
Also this PR has changed it together as it is necessary to enable
`Layout/ElseAlignment` cop to make this behavior.
pg-1.0.0 is just released and most Gemfiles don't restrict
it's version. But the version is checked when connecting to
the database, which leads to the following error:
Gem::LoadError: can't activate pg (~> 0.18), already activated pg-1.0.0
See also this pg issue:
https://bitbucket.org/ged/ruby-pg/issues/270/pg-100-x64-mingw32-rails-server-not-start
Preparation for pg-1.0 was done in commit f28a331023fab,
but the pg version constraint was not yet relaxed.
Remove `AppGeneratorTest#test_active_storage_install`.
The test is added by 67db41aa7f17c2d34eb5a914ac7a6b2574930ff4,
since #31534 this test doesn't test anything.
Remove redundant assertions in `SharedGeneratorTests`.
These assertions is added by 4a835aa3236eedb135ccf8b59ed3c03e040b8b01.
Follows 67db41aa7f17c2d34eb5a914ac7a6b2574930ff4, #31534.
Otherwise, at least using JRuby, the replacements in
convert_database_option_for_jruby won't work. Thus a call to
bundle exec rails app:update
fails. Simply replacing those replace statements doesn't seem to work
either, since the options hash seems to be frozen, too.
Instead of providing a configuration option to set the hash function,
switch to SHA-1 for new apps and allow upgrading apps to opt in later
via `new_framework_defaults_5_2.rb`.
Enabling this option in new_framework_defaults_5_2.rb didn't work
before, as railtie initializers run before application initializers.
Using `respond_to?` to decide whether to set the option wasn't working
either, as `ActiveSupport::OrderedOptions` responds to any message.
Before Rails 4.0, `config.cache_classes` determined whether application
code was eager loaded. The `config.eager_load` option was introduced to
allow the two behaviours to be configured independently, but this
documentation was never updated to reflect that change.
Currently the comment says application configuration should go into
files in `config/initializers`.
However some configuration couldn't initialize correctly because of the
initializing process(e.g. `config.time_zone`).
It should be changed by framework but this is large change and it may occur
malfunction to some applications which depends on current initializing
process.
So this comment is changed to adapt to the fact.
Puma gets bundler's info from `Bundler::ORIGINAL_ENV` for restart.
f6f3892f4d/lib/puma/launcher.rb (L168)
So, specified `BUNDLE_GEMFILE` env for use same Gemfile in the restart.
Fixes#31351
This pull request handles `FrozenError` introduced by Ruby 2.5.
Refer https://bugs.ruby-lang.org/projects/ruby-trunk/repository/revisions/61131
Since `FrozenError` is a subclass of `RuntimeError` minitest used by master
branch can handle it, though it would be better to handle `FrozenError`
explicitly if possible.
`FrozenError` does not exist in Ruby 2.4 or lower, `frozen_error_class`
handles which exception is expected to be raised.
This pull request is intended to be merged to master,
then backported to `5-1-stable` to address #31508
The `app:update` rake task will regenerate `development.rb` so that it
contains this option; that means we're currently adding it to existing
apps in two places, which is unnecessary and confusing.
Also:
- Remove inaccurate comment about which stack frames are ignored
- Clarify that the feature uses `caller_locations`, not `caller`
- Remove unused return value in `extract_callstack`
`bootsnap` is a useful gem normally. However, `bootsnap` is unnecessary
when generating a Rails application to be used only for testing.
So I want to control whether use this or not by option.
I've noticed during pair/mob programming sessions with peers that
despite the speed boosts provided by Bootsnap and Spring, there is a
noticeable latency between firing a bin/rails server command and any
feedback being provided to the console. Depending on the size of the
application this lack of feedback can make it seem like something is
wrong when Rails is simply busy initializing.
This change may seem gratuitous but by just printing one line to STDOUT
we're giving a clear signal to the Rails user that their command has
been received and that Rails is indeed booting. It almost imperciptibly
makes Rails feel more responsive.
Sure the code doesn't look very fancy but there's no other appropriate
place I could think of putting it than boot.rb.
Compare these two GIFs of booting without and with this change:
Before:
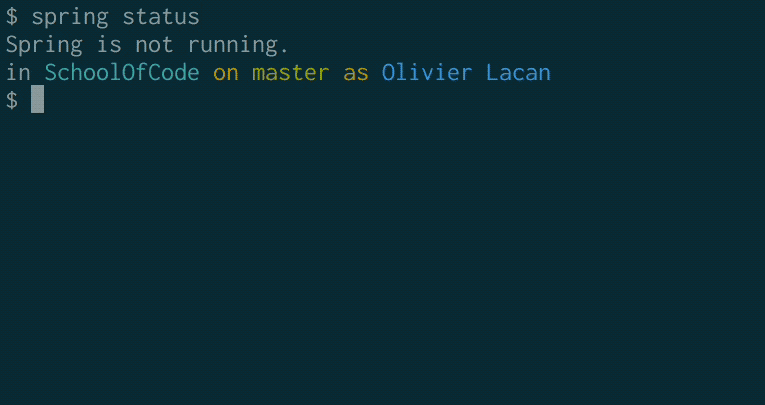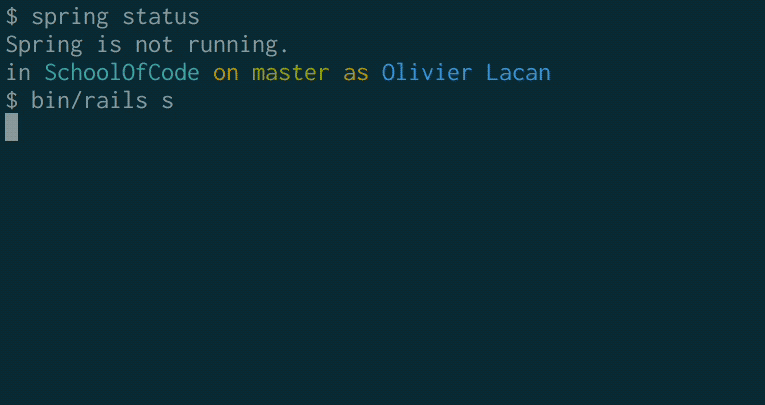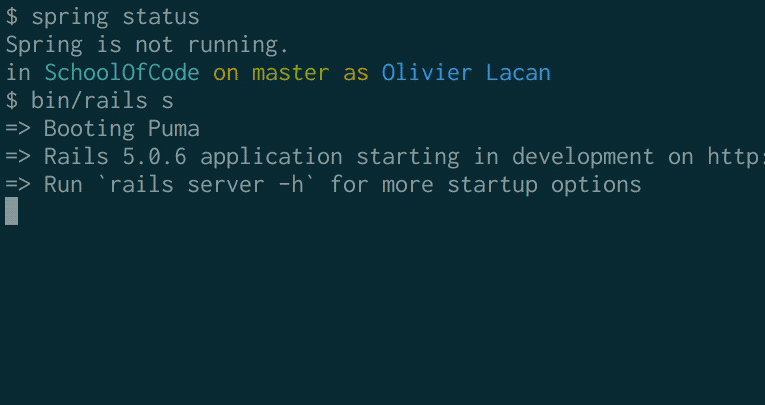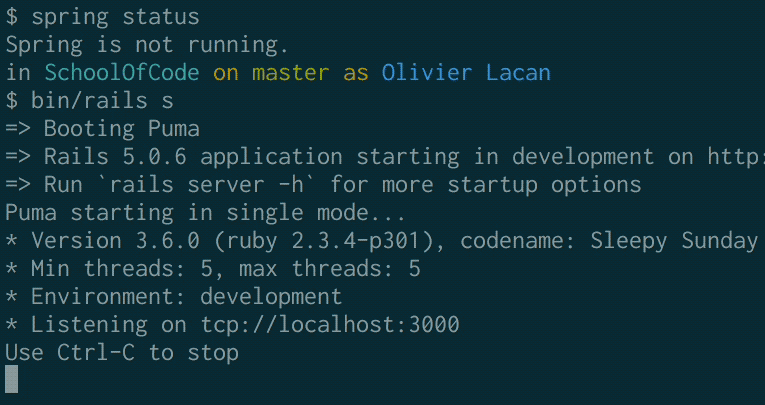
After:

This new ActiveRecord configuration option allows you to easily
pinpoint what line of application code is triggering SQL queries in the
development log by appending below each SQL statement log the line of
Ruby code that triggered it.
It’s useful with N+1 issues, and to locate stray queries.
By default this new option ignores Rails and Ruby code in order to
surface only callers from your application Ruby code or your gems.
It is enabled on newly generated Rails 5.2 applications and can be
enabled on existing Rails applications:
```ruby
Rails.application.configure do
# ...
config.active_record.verbose_query_logs = true
end
```
The `rails app:upgrade` task will also add it to
`config/development.rb`.
This feature purposely avoids coupling with
ActiveSupport::BacktraceCleaner since ActiveRecord can be used without
ActiveRecord. This decision can be reverted in the future to allow more
configurable backtraces (the exclusion of gem callers for example).
- The namespacing should be `ActiveRecord::FixtureSet`
- I might be missing something but I'm not sure why `create_fixtures` is useful for nowaday (unless for testing rails internal /shrug) and since it's been that long it wasn't working I think it should be fine to just fire it
Option parsing happens too late to have any impact on the Rails
environment. Rails accesses the environment name and memoizes it too
early in the boot process for a commandline option to have any impact on
the database connection, so we'll change this test to set the
environment from an environment variable (and ensure it still works when
running tests with `ruby`)
When tests are run with just `ruby`, the RAILS_ENV is set to
`development` too early, and we connect to the development database
rather than the test database.
I frequently run tests with `ruby`, not with a runner like `rake` or
`rails`. When running the test with just `ruby` the `RAILS_ENV`
environment variable did not get set to "test", and this would cause the
tests to fail (and even mutate the development database!)
This commit adds integration tests for running tests with just `ruby`
and ensures the environment gets defaulted to "test". I also added a
test to ensure that passing an environment to `-e` actually works (and
fixed that case too).
An interesting / annoying thing is that Minitest picks up it's plugins
by asking RubyGems for a list of files:
ca6a71ca90/lib/minitest.rb (L92-L100)
This means that RubyGems needs to somehow know about the file before it
can return it to Minitest. Since we are not packaging Rails as a Gem
before running the integration tests on it (duh, why would you do
that?), RubyGems doesn't know about the file, so it can't tell Minitest,
so Minitest doesn't automatically require it. This means I had to
manually require and insert the plugin in our integration test. I've
left comments about that in the test as well.
Ugh.
With the current code, a failing test shows this error, which is missing
the number of times called and has two periods at the end.
```
/railties$ be ruby -Itest test/generators/app_generator_test.rb -n test_active_storage_install
Failure:
AppGeneratorTest#test_active_storage_install [test/generators/app_generator_test.rb:313]:
active_storage:install expected to be called once, but was called times..
Expected: 1
Actual: 2
```
After the fix, the error message looks correct:
```
/railties$ be ruby -Itest test/generators/app_generator_test.rb -n test_active_storage_install
Failure:
AppGeneratorTest#test_active_storage_install [test/generators/app_generator_test.rb:313]:
active_storage:install expected to be called once, but was called 2 times.
Expected: 1
Actual: 2
```
In order to use early hints, need to use Puma 3.11.0 or higher.
So, I think that should specify that version in newly generated applications.
Ref: f6f3892f4d
In some places this file referred to the database in three different ways: database, DB and db. The last one caused confusion with the db namespace and the db folder. This commit removes this ambiguity by using the whole word 'database' everywhere
This was added with 27f103fc7e3260efe0b8dde66bf5354f2202ee32 for link labels and fields.
However, `form_with` changed to generates ids by default with d3893ec38ec61282c2598b01a298124356d6b35a.
So I think that adding an explicit ids is unnecessary.
When `form_with` was introduced we disabled the automatic
generation of ids that was enabled in `form_for`. This usually
is not an good idea since labels don't work when the input
doesn't have an id and it made harder to test with Capybara.
You can still disable the automatic generation of ids setting
`config.action_view.form_with_generates_ids` to `false.`
Since fbd1e98cf983572ca9884f17f933ffe92833632a, Rails plugin does not
run `bundle install` when generating.
Therefore, `after_bundle` callback is not actually executed after `bundle`.
Since there is a difference between the name and the actual behavior,
I think that should be remove.
We generate master key on `rails new`.
Therefore, if do not add master key to `.gitginore` on `rails new`as
well, there is a possibility that the master key will be committed
accidentally.
Currently the environment is not loaded in some db tasks.
Therefore, if use encrypted secrets values in `database.yml`,
`read_encrypted_secrets` will not be true, so the value can not be
used correctly.
To fix this, added `environment` as dependency of `load_config`.
It also removes explicit `environment` dependencies that are no longer
needed.
Fixes#30717
Allow edits of existing encrypted secrets generated on Rails 5.1,
but refer to credentials when attempting to setup.
This also removes the need for any of the setup code, so the
generator can be ripped out altogether.
Since credentials generator is executed via the credentials command and
does not need to be executed directly, so it is not necessary to show it in
help.
In order to execute the `rails` command, need to run bundle install in
advance.
Therefore, if skipped bundle install, `rails` command may fail and
should not do it.
Ensure that `bin/rails db:migrate` with specified `VERSION` reverts
all migrations only if `VERSION` is `0`.
Raise error if target migration doesn't exist.
Omit `rails activestorage:install` for jdbcmysql, jdbc and shebang tests
AppGeneratorTest#test_config_jdbcmysql_database
rails aborted!
LoadError: Could not load 'active_record/connection_adapters/mysql_adapter'.
Make sure that the adapter in config/database.yml is valid.
If you use an adapter other than 'mysql2', 'postgresql' or 'sqlite3' add
the necessary adapter gem to the Gemfile.
(compressed)
bin/rails:4:in `<main>'
Tasks: TOP => activestorage:install => environment
(See full trace by running task with --trace)
AppGeneratorTest#test_config_jdbc_database
rails aborted!
LoadError: Could not load 'active_record/connection_adapters/jdbc_adapter'.
Make sure that the adapter in config/database.yml is valid.
If you use an adapter other than 'mysql2', 'postgresql' or 'sqlite3' add
the necessary adapter gem to the Gemfile.
(compressed)
bin/rails:4:in `<main>'
Tasks: TOP => activestorage:install => environment
(See full trace by running task with --trace)
AppGeneratorTest#test_shebang_is_added_to_rails_file
/home/ubuntu/.rbenv/versions/2.4.1/bin/ruby: no Ruby script found in input (LoadError)
Prevent PendingMigrationError in tests
* Run `bin/rails db:migrate RAILS_ENV=test` in test_cases before start tests to prevent PendingMigrationError
* FileUtils.rm_r("db/migrate")
* --skip-active-storage
Fix failed tests in `railties/test/railties/engine_test.rb`
Related to #30111
Imporve `SharedGeneratorTests#test_default_frameworks_are_required_when_others_are_removed`
- Explicitly skip active_storage
- Ensure that skipped frameworks are commented
- Ensure that default frameworks are not commented
Fix error `Errno::ENOSPC: No space left on device - sendfile`
Since `rails new` runs `rails active_storage:install`
that boots an app.
Since adding Bootsnap 0312a5c67e35b960e33677b5358c539f1047e4e1
during booting an app, it creates the cache:
264K tmp/cache/bootsnap-load-path-cache
27M tmp/cache/bootsnap-compile-cache
* teardown_app must remove app
Closes#30102
Revert part 787fe90dc0a7c5b91bb5af51f2858ea8c4676268
--skip-active-storage pass throughs `rails plugin new`
Add changelog entry about default initialization of Active Storage
{kind=link}
{kind=link}