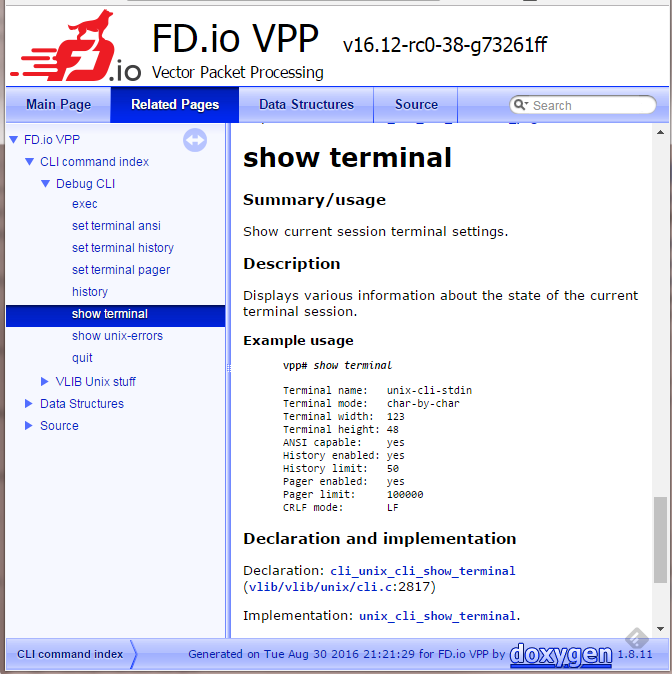
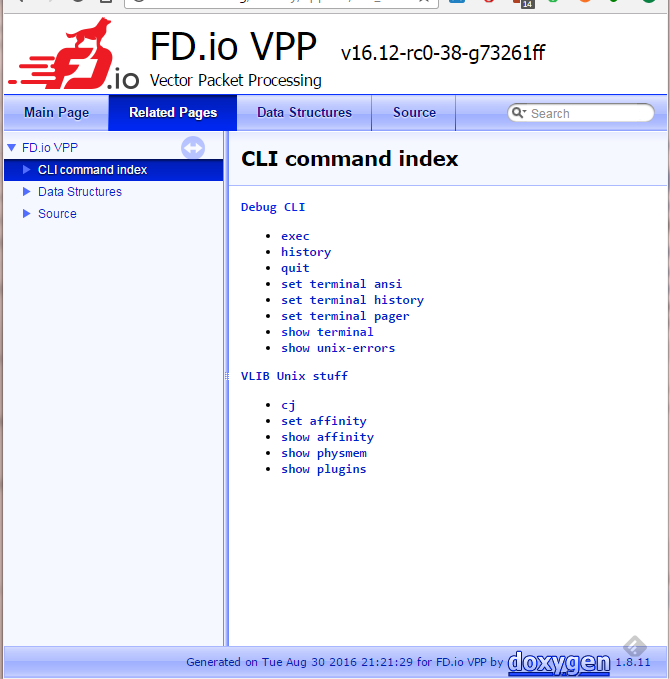
As a step before Doxygen, extract CLI-related struct initializers from the code and parse that into a summary of the CLI commands available with the provided help text, such as it is. At the moment this only renders this into an indexed Markdown file that Doxygen then picks up but later we can use this information to enrich the existing VLIB_CLI_COMMAND macro documentor as well as provide runtime documentation to VPP that is stored on disk outside the binary image. Additionally support a comment block immediately prior to VLIB_CLI_COMMAND CLI command definitions in the form /*? ... ?*/ that can be used to include long-form documentation without having it compiled into VPP. Examples of documenting CLI commands can be found in vlib/vlib/unix/cli.c which, whilst not perfect, should provide a starting point. Screen captures of sample output can be seen at https://chrisy.flirble.org/vpp/doxy-cli-example.png and https://chrisy.flirble.org/vpp/doxy-cli-index.png . Next, shift the Doxygen root makefile targets to their own Makefile. The primary reason for this is that the siphon targets do dependency tracking which means it needs to generate those dependencies whenever make is run; that is pointless if we're not going to generate any documentation. This includes the package dependencies since they since they sometimes unnecessarily interfere with the code build in some cases at the moment; later we will look to building a Python venv to host the Python modules we use. One final remark: In future we may consider deprecating .long_help in the VLIB_CLI_COMMAND structure entirely but add perhaps .usage_help. .short_help would be reserved for a summary of the command function and .usage_help provide the syntax of that command. These changes would provide great semantic value to the automaticly generated CLI documentation. I could also see having .long_help replaced by a mechanism that reads it from disk at runtime with a rudimentary Markdown/Doxygen filter so that we can use the same text that is used in the published documentation. Change-Id: I80d6fe349b47dce649fa77d21ffec0ddb45c7bbf Signed-off-by: Chris Luke <chrisy@flirble.org>
{kind=link}
{kind=link}
Vector Packet Processing
Introduction.
The VPP platform is an extensible framework that provides out-of-the-box production quality switch/router functionality. It is the open source version of Cisco's Vector Packet Processing (VPP) technology: a high performance, packet-processing stack that can run on commodity CPUs.
The benefits of this implementation of VPP are its high performance, proven technology, its modularity and flexibility, and rich feature set.
For more information on VPP and its features please visit the FD.io website and What is VPP? pages.
Directory layout.
| Directory name | Description |
|---|---|
| build-data | Build metadata |
| build-root | Build output directory |
| doxygen | Documentation generator configuration |
| dpdk | DPDK patches and build infrastructure |
| g2 | Event log visualization tool |
| gmod | perf related? |
| perftool | Performance tool |
| plugins | VPP bundled plugins directory |
| @ref svm | Shared virtual memory allocation library |
| test | Unit tests |
| @ref vlib | VPP application library source |
| @ref vlib-api | VPP API library source |
| @ref vnet | VPP networking source |
| @ref vpp | VPP application source |
| @ref vpp-api | VPP application API source |
| vppapigen | VPP API generator source |
| vpp-api-test | VPP API test program source |
| @ref vppinfra | VPP core library source |
(If the page you are viewing is not generated by Doxygen then ignore any @@ref labels in the above table.)
Getting started.
In general anyone interested in building, developing or running VPP should consult the VPP wiki for more complete documentation.
In particular, readers are recommended to take a look at [Pulling, Building, Running, Hacking, Pushing](https://wiki.fd.io/view/VPP/Pulling,_Building,_Run ning,_Hacking_and_Pushing_VPP_Code) which provides extensive step-by-step coverage of the topic.
For the impatient, some salient information is distilled below.
Quick-start: On an existing Linux host.
To install system dependencies, build VPP and then install it, simply run the
build script. This should be performed a non-privileged user with sudo
access from the project base directory:
./build-root/vagrant/build.sh
If you want a more fine-grained approach because you intend to do some
development work, the Makefile in the root directory of the source tree
provides several convenience shortcuts as make targets that may be of
interest. To see the available targets run:
make
Quick-start: Vagrant.
The directory build-root/vagrant contains a VagrantFile and supporting
scripts to bootstrap a working VPP inside a Vagrant-managed Virtual Machine.
This VM can then be used to test concepts with VPP or as a development
platform to extend VPP. Some obvious caveats apply when using a VM for VPP
since its performance will never match that of bare metal; if your work is
timing or performance sensitive, consider using bare metal in addition or
instead of the VM.
For this to work you will need a working installation of Vagrant. Instructions for this can be found [on the Setting up Vagrant wiki page] (https://wiki.fd.io/view/DEV/Setting_Up_Vagrant).
More information.
Visit the VPP wiki for details on more advanced building strategies and development notes.